

K8S. Ancora su Kubernetes.
K8S. Ancora su Kubernetes.
Continua il nostro viaggio su Kubernets. Scopriremo oggi altri dettagli che vi aiuteranno a migliorare la gestione di questa oramai diffusissima piattaforma open-source.
K8S. Inefficient resource utilization.
La maggior parte dei problemi del sistema Kubernetes è causata da errata configurazione delle risorse del gestore del contenitore. Ogni volta che viene pianificato un carico di lavoro, il contenitore può richiedere la quantità richiesta di risorse di CPU e memoria. Lo scheduler Kubernetes assegna quindi il nodo giusto al pod che può occuparsi dell’attività in base alla quantità di risorse richieste. In genere viene specificato un valore per garantire che Kubernetes assegni risorse nodali sufficienti a un pod senza superare il limite. Quando un contenitore alloca più risorse di quelle disponibili, l’applicazione rallenta e ne risulta un utilizzo eccessivo. Il sottoutilizzo si verifica quando le risorse richieste allocano più di quanto viene utilizzato, il che tende anche a rallentare l’applicazione.
K8S. Limiti.
È possibile impostare un limite per limitare la quantità di risorse a cui il contenitore può accedere. Questi vincoli sono preconfigurati all’interno del pod per garantire che il carico di lavoro venga eseguito senza alcun ritardo e non ostacoli l’avanzamento degli altri. Ogni volta che viene effettuata una richiesta di CPU o memoria, il limite di utilizzo viene impostato su un valore tale che vi sia spazio sufficiente per far fronte a un uso eccessivo di tali risorse. Ma cosa succede se il pod consuma più di quanto è consentito? Può portare a due problemi principali di Kubernetes.
K8S. CPU throttling.
La limitazione della CPU si verifica quando l’utilizzo della CPU si avvicina al limite della CPU. Poiché il limite specifica l’utilizzo massimo della CPU disponibile per il pod, l’applicazione non avrà accesso a una quantità adeguata di risorse necessarie per eseguire il carico di lavoro. Il pod potrebbe successivamente arrestarsi e riavviarsi. Come meccanismo di risposta, la CPU viene limitata per ridurre al minimo l’utilizzo della CPU, il che rallenta l’applicazione.
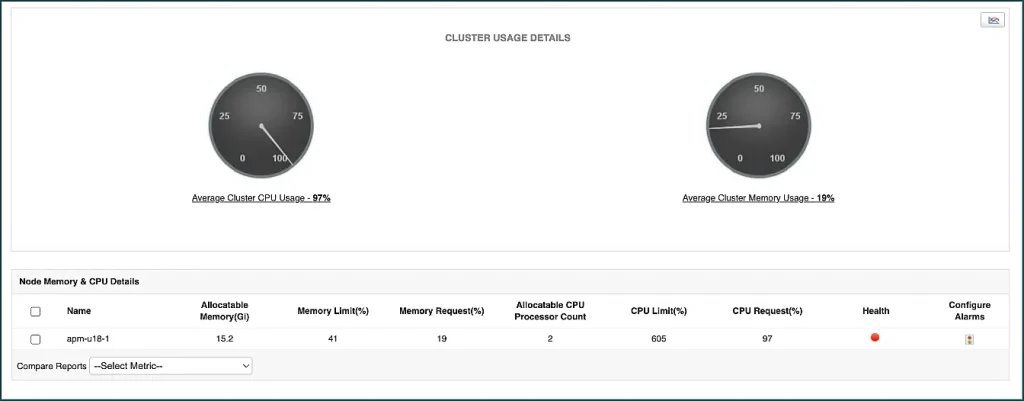
K8S. OOMKilled.
Il codice di errore OOMKilled si verifica quando il contenitore consuma più risorse di memoria di quelle allocate. Quando l’utilizzo della memoria tenta di superare il limite di memoria, il processo associato viene OOMKilled (Out of Memory Killed) o terminato. Il kubelet può quindi riavviare il pod e provare ad allocare memoria in base alla richiesta. Se il pod si riavvia, ci sarà un certo ritardo dovuto al tempo di caricamento che avrà un impatto sull’applicazione contenitore. ManageEngine Applications Manager raccoglie dati per visualizzare il valore limite di CPU e memoria per ciascun pod. Il monitor di questa soluzione tiene traccia anche dello stato del pod, dell’attività di utilizzo della CPU e della memoria del cluster e dei conteggi del processore CPU allocabile per ciascun nodo. Inoltre, il monitor visualizza grafici che mostrano i primi 5 nodi o pod che possono facilmente identificare i componenti che hanno superato il loro limite di richiesta.

Analizzando collettivamente questi dati, è possibile prendere decisioni per rimuovere o modificare il limite imposto ai pod. Aiutare a contrastare la limitazione della CPU e il codice di errore OOMkilled.
K8S. CrashLoopBackOff error.
Risorse di CPU o memoria insufficienti. I pod potrebbero essere terminati senza poter essere pianificati su un nodo. Ciò richiede al kubelet di riavviare il pod non riuscito. Sarà quindi soggetto a un nuovo arresto anomalo. Andrà inserito un ciclo che attiva il codice di errore CrashLoopBackOff. Ogni volta che il contenitore esegue un riavvio, il tempo di caricamento aumenta in modo esponenziale. Il codice di errore CrashLoopBackOff può essere visualizzato anche ogni volta che un contenitore viene avviato per la prima volta ed entra in un ciclo. Alcuni degli altri colpevoli responsabili dell’errore CrashLoopBackOff sono configurazioni errate, mancata corrispondenza dei nomi delle risorse, risorse bloccate e problemi di connettività.

K8S. ErrImagePull error.
ErrImagePull è un altro errore. Si verifica ogni volta che un pod non è in grado di estrarre l’immagine richiesta dal registro del contenitore. Il pod passa quindi allo stato ErrImageBackOff. Un motivo è quando il nome dell’immagine del contenitore specificato nel pod del contenitore non è corretto. Il recupero dell’immagine sbagliata può anche portare a un errore del pod che può rivelarsi fatale per le operazioni dell’applicazione. L’utilizzo di Applications Manager aiuta a eseguire un controllo approfondito sul loro sistema di container per identificare potenziali mancate corrispondenze. Possono quindi modificare la specifica del pod per fornire il nome corretto ed estrarre manualmente l’immagine. Puoi anche visualizzare il numero totale di immagini disponibili in ciascun nodo all’interno della nostra dashboard Kubernetes.
Segui le prossime puntate per approfondire e scopri come monitorare le applicazioni con Applications Manager: https://www.manageengine.it/applications_manager/ e contattaci per maggiori dettagli! Chiama lo 0643230077 o invia una e-mail a sales@bludis.it
Redazione
Bludis è il distributore ufficiale in Italia delle soluzioni ManageEngine. Da 30 anni si occupa della distribuzione di soluzioni ICT e della fornitura di una vasta gamma di servizi a valore aggiunto per consentire il massimo livello di soddisfazione possibile per Vendor, Reseller e End-User