


OpenShift. Come monitorarlo.
OpenShift. Come monitorarlo.
La maggior parte delle aziende IT costruisce il proprio impero su Kubernetes. È flessibilite e scalabile. RedHat OpenShift Container Platform (in precedenza OpenShift Enterprise) è una piattaforma applicativa cloud ibrida basata su Kubernetes. Inizialmente operava solo on-premise ed è aperta al servizio da più di nove anni. Data la crescente passione per il monitoraggio del cloud ibrido, le aziende si stanno rivolgendo alla piattaforma OpenShift Container per creare, distribuire e gestire applicazioni native del cloud. Non importa quanto scalabile e flessibile sia il software. È difficile evitare i punti ciechi e rimanere informati sul suo comportamento. L’infrastruttura multilivello e le enormi implementazioni rendono difficile ottenere una visibilità completa. Per sfruttare tutto il potenziale di una piattaforma come OpenShift, bisogna avere una chiara panoramica dell’infrastruttura e di una conoscenza approfondita dei KPI critici per il business.
Cosa monitorare.
Ecco i cinque elementi cruciali di OpenShift e i rispettivi parametri a cui un amministratore IT dovrebbe prestare attenzione durante il monitoraggio di un ambiente OpenShift.
Nodi.
Indipendentemente dalla funzionalità di un nodo, l’amministratore deve monitorare ciascun nodo associato all’infrastruttura OpenShift. Parametri come utilizzo della CPU, spazio su disco e utilizzo della memoria di ogni nodo devono essere monitorati in tempo reale.
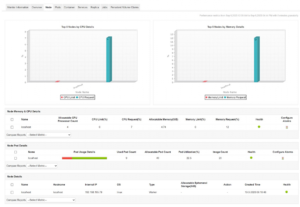
Il monitoraggio periodico dei nodi e il mantenimento del punteggio sull’andamento delle prestazioni aiuta ad analizzare il comportamento degli elementi. Ciò aiuta l’amministratore a correlare il comportamento e l’interdipendenza dei parametri e a prevedere con precisione le tendenze future. L’amministratore può eliminare in modo proattivo la possibilità di colli di bottiglia e traffico imprevisto monitorando l’ecosistema fino all’ultimo dettaglio.
Pods.
Immagina che un pod venga utilizzato per eseguire una funzione prioritaria per un determinato periodo di tempo. Se il pod si blocca o muore, sarebbe un compito noioso rintracciare la causa principale del malfunzionamento in un ambiente complesso come OpenShift.
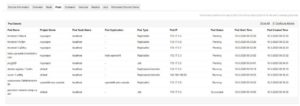
Il monitoraggio di ciascun pod in tempo reale aiuta a tenere traccia dei KPI, dell’attività e del consumo di risorse. Ciò fa luce sulle cause profonde che sono responsabili di errori e rallentamenti.

Segui anche la prossima puntata per approfondire l’argomento. Se vuoi maggiori informazioni consulta la nostra pagina: https://www.manageengine.it/applications_manager/ o contattaci. Invia una e-mail a sales@bludis.it o chiama lo 0643230077.
Redazione
Bludis è il distributore ufficiale in Italia delle soluzioni ManageEngine. Da 30 anni si occupa della distribuzione di soluzioni ICT e della fornitura di una vasta gamma di servizi a valore aggiunto per consentire il massimo livello di soddisfazione possibile per Vendor, Reseller e End-User