


Elasticsearch. Monitoriamo le performance.
Elasticsearch. Monitoriamo le sue performance.
Elasticsearch è un motore di analisi e ricerca RESTful altamente scalabile, distribuito e open-source che offre analisi dei log, monitoraggio delle applicazioni in tempo reale, analisi dei flussi di clic e altro ancora. Elasticsearch memorizza e recupera strutture dati in tempo reale. Ha funzionalità multi-tenant con un’interfaccia web HTTP, presenta i dati sotto forma di documenti JSON strutturati, rende la ricerca full-text accessibile tramite RESTful API e mantiene client Web per lingue come PHP, Ruby, .Net e Java.
L’unico modo per sfruttare appieno queste capacità è utilizzare gli strumenti di monitoraggio che ti danno una visibilità profonda nel tuo ambiente Elasticsearch. Gli strumenti giusti possono trasformare i dati in informazioni utili. Il monitoraggio delle prestazioni del tuo ambiente Elasticsearch con i dati aggregati più recenti ti aiuta a rimanere aggiornato sui componenti interni del tuo working cluster. Per quanto riguarda il monitoraggio di Elasticsearch, ci sono un sacco di parametri da considerare: qui, daremo un’occhiata più da vicino a quattro importanti parametri che dovresti tenere sul tuo radar.
Elasticsearch. Cosa monitorare.
Di seguito un breve elenco di key performance da monitorare.
Elasticsearch. Cluster health and node availability.
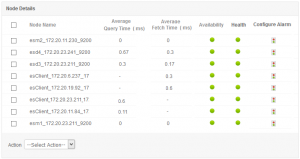
Le prestazioni di un server Elasticsearch dipendono fortemente dalla macchina in cui è installato. Per rimanere aggiornato sullo stato del cluster, è fondamentale monitorare le metriche delle prestazioni chiave come I/O del disco, utilizzo della CPU per tutti i nodi, utilizzo della memoria e integrità del nodo (in tempo reale) per ciascun nodo Elasticsearch. È meglio esaminare le metriche Java Virtual Machine (JVM) quando si verificano picchi di CPU. Poiché Elasticsearch viene eseguito all’interno di JVM, il monitoraggio dell’utilizzo della memoria richiede la verifica delle statistiche della memoria JVM e della garbage collection.
Elasticsearch. Index performance metric.
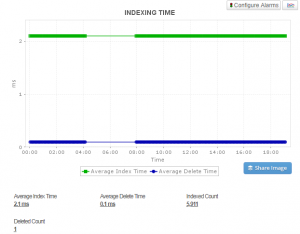
Durante l’esecuzione dei benchmark di indicizzazione, viene utilizzato un numero fisso di record per calcolare il tasso di indicizzazione. Quando il carico di lavoro è pesante, l’aggiornamento degli indici con nuove informazioni rende più semplice il monitoraggio e l’analisi delle prestazioni di Elasticsearch. Picchi improvvisi e cadute nei tassi di indicizzazione potrebbero indicare problemi con le fonti di dati. Le prestazioni complessive del cluster possono essere influenzate dal tempo di aggiornamento e dal tempo di unione.
Solitamente sono preferiti tempi di aggiornamento ridotti e tempi di unione rapidi. Ottimali strumenti di monitoraggio delle prestazioni di Elasticsearch consentono di monitorare la latenza media delle query per ogni nodo, inclusi ora di inizio, tempo medio di segmento nel nodo, utilizzo della cache del file system e tassi di richiesta nonché aiuto nella configurazione delle azioni in caso di violazione delle soglie.
Elasticsearch. Search performance metric.
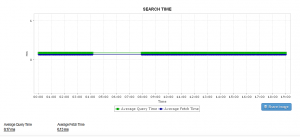
Oltre alle richieste di indice, un’altra richiesta importante è la richiesta di ricerca. Ecco alcune importanti metriche sul rendimento della ricerca da tenere in considerazione durante l’esecuzione del monitoraggio Elasticsearch:
Query latency & request rate: Vi sono numerose cose che possono influenzare le prestazioni della query come query mal costruite, cluster Elasticsearch configurati in modo errato, memoria JVM, problemi di garbage collection, ecc. Senza dubbio, la latenza delle query è una metrica che ha un impatto diretto sugli utenti, ed è essenziale ricevere avvisi quando c’è un’anomalia. Il monitoraggio del tasso di richiesta insieme alla latenza delle query fornisce una panoramica di quanto viene utilizzato un sistema.
Filter cache: i filtri in Elasticsearch vengono memorizzati nella cache per impostazione predefinita. Durante l’esecuzione di una query con un filtro, Elasticsearch troverà i documenti corrispondenti al filtro e costruirà una struttura chiamata bitset utilizzando tali informazioni. Se le esecuzioni successive della query hanno lo stesso filtro, le informazioni memorizzate nel bitset verranno riutilizzate, rendendo più veloce l’esecuzione della query salvando le operazioni di I/O ei cicli della CPU.
Elasticsearch. Network and thread pool monitoring.
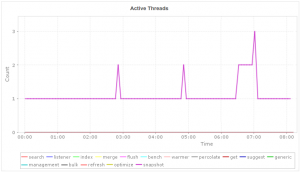
I nodi Elasticsearch utilizzano i pool di thread per gestire la memoria dei thread e il consumo della CPU. I pool di thread vengono automaticamente configurati in base al numero di processori. I pool di thread importanti da monitorare includono: ricerca, indice, unione e massa. I problemi relativi al pool di thread possono essere causati da un numero elevato di richieste in sospeso o da un singolo nodo lento nonché da un rifiuto del pool di thread. Un drastico cambiamento nell’utilizzo della memoria o nella lunga raccolta di dati inutili potrebbe indicare una situazione critica. Troppe attività di garbage collection possono verificarsi per due motivi:
- Un particolare pool è “stressato”
- La JVM ha bisogno di più memoria di quella che gli è stata assegnata.
Per evitare picchi nel pool di thread, prepararsi ai problemi del pool di thread causati da richieste in sospeso, un singolo nodo lento o reiezioni del pool di thread nella coda di indicizzazione.
Applications Manager di ManageEngine, semplifica il monitoraggio di Elasticsearch offrendo una overview immediata per il server con approfondimenti che identificano facilmente i nodi problematici con analisi delle cause principali dei problemi di prestazioni.
Vuoi testare subito le funzionalità di Applications Manager? scarica la versione demo gratuita dal nostro sito: http://www.manageengine.it/applications_manager/
Se invece ti interessa avere informazioni di carattere tecnico o commerciale contattaci allo 0643230077 o invia una e-mail a sales@bludis.it
Redazione
Bludis è il distributore ufficiale in Italia delle soluzioni ManageEngine. Da oltre 25 anni si occupa della distribuzione di soluzioni ICT e della fornitura di una vasta gamma di servizi a valore aggiunto per consentire il massimo livello di soddisfazione possibile per Vendor, Reseller e End-User