


Infrastructure stability
Con questa serie di articoli, abbiamo deciso di illustrarvi gli otto KPI fondamentali per ogni Help Desk IT: aiutano a raggiungere gli obiettivi quali business continuity, produttività organizzativa, erogazione di servizi nei tempi stability e rispetto del budget. Questa volta parleremo della stabilità dell’infrastruttura. Una infrastruttura può definirsi altamente stabile quando è caratterizzata da massima disponibilità, pochissime interruzioni, basse interruzioni di servizio.
Obiettivo: mantenere una infrastruttura altamente stabile.
Per misurare e monitorare la stabilità dell’infrastruttura in modo efficace, l’help desk ha bisogno di monitorare:
- Riduzione in percentuale del numero di assets problematici
- Percentuale di riduzione del numero di incident “gravi”
Infrastructure stability: percentuale di riduzione delle problematiche sugli assets
Offrire massima disponibilità e qualità del servizio è impossibile in un’infrastruttura dove i router devono essere riavviati più volte al giorno, i server sono spesso giù o le workstation devono essere riavviate in continuazione. Queste problematiche devono essere individuate e risolte per garantire continuità al business. Un asset che crea problemi, può essere la causa di diverse interruzioni del servizio che potrebbero inficiare anche altre attività all’interno dell’azienda. La percentage reduction del numero di asset problematici, può essere calcolata facendo il rapporto tra: numero di asset problematici sostituiti nel periodo di tempo stabilito in funzione del numero di asset problematici identificati all’inizio dello stesso periodo.
Infrastructure stability: percentuale di riduzione degli incident più seri.
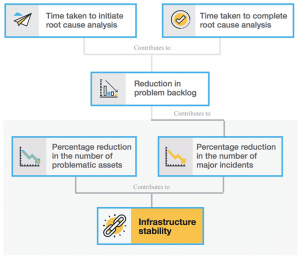
Un’altra importante indicazione di stabilità è il ripetersi di incident di rilievo sull’infrastruttura IT, che può portare a interruzioni di servizio o peggioramento del livello di servizio erogato. Un incident grave è per definizione, un problema che impatta in maniera urgente colpendo un gran numero di utenti e interrompendo una o due attività chiave per l’azienda. L’obiettivo è ridurre al minimo il numero di incident gravi effettuando una efficiente RCA (root cause analysis) e riducendo i problemi in backlog. Possiamo così ridurre il numero di incident “gravi” e di conseguenza il numero di chiamate all’help desk.
Suggerimenti per ridurre problemi in backlog (e quindi gli incident più gravi).
- Velocità nell’implementazione di una efficiente RCA (root cause analysis): prima si comincia e maggiori sono le probabilità di identificare la causa principale.
- Rapidità d’azione: se la causa principale è individuata velocemente, il team IT può risolvere prima il problema facendo si che non si ripresenti.
I team possono misurare questi elementi, mediante i dettagli sul tempo necessario per avviare la RCA dopo l’identificazione del problema ed il tempo necessario per completarla. Le principali cause per problemi in backlog possono essere:
- Ritardo o tempi lunghi nella RCA.
- Poca qualità della RCA e mancanza di documentazione.
- Comunicazione poco efficace del processo ai responsabili.
Non identificando la RCA, le probabilità di incident gravi sono alte e ricorrenti. Il problema del backlog può essere ridotto con:
- Un team dedicato al Problem Management con problem administrators and problem managers.
- Identificando e formando esperti in materia.
- Training del problem management team sulle tecniche base e avanzate per la RCA.
Lavorando su questi due parametri – percentuale di riduzione del numero di incident gravi e percentuale di riduzione del numero di asset problematici – può aiutare a mantenere un’infrastruttura IT altamente stabile.
Case study: ridurre il numero di incident gravi e migliorare la stabilità dell’IT
Una delle istituzioni finanziarie più importanti del mondo, ha migliorato la sua stabilità riducendo gli incident di rilievo. Tale riduzione del numero di incident, è stata possibile migliorando il processo di analisi delle cause.

Nel prossimo articolo tratteremo un altro KPI molto importante: il volume dei tickets aperti. Nel frattempo, se siete alla ricerca di una soluzione end to end per la gestione del servizio IT della vostra azienda, potete scaricare la versione gratuita di ServiceDesk Plus di ManageEngine http://www.manageengine.it/service-desk/ il software di HelpDesk utilizzato da oltre 185 paesi!
Se vuoi avere maggiori informazioni puoi contattare i nostri specialisti di prodotto telefonicamente allo 0643230077 o via email su sales@bludis.it
Redazione
Bludis è il distributore ufficiale in Italia delle soluzioni ManageEngine. Da oltre 25 anni si occupa della distribuzione di soluzioni ICT e della fornitura di una vasta gamma di servizi a valore aggiunto per consentire il massimo livello di soddisfazione possibile per Vendor, Reseller e End-User